When using the .apply() method on a grouped DataFrame in pandas, you may encounter the following warning:
DeprecationWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.What Does This Mean?
This warning indicates that the grouping column(s) are still present in the resulting DataFrame after applying a function. Since these columns already serve as the index, their inclusion is often redundant.
Example
Consider the following DataFrame:
df = pd.DataFrame([
('Jack', 'Male', 10000),
('Anne', 'Female', 12000),
('Kate', 'Female', 15000),
('Dan', 'Male', 8000),
('Alice', 'Female', 9000)
], columns=['Name', 'Gender', 'Salary'])
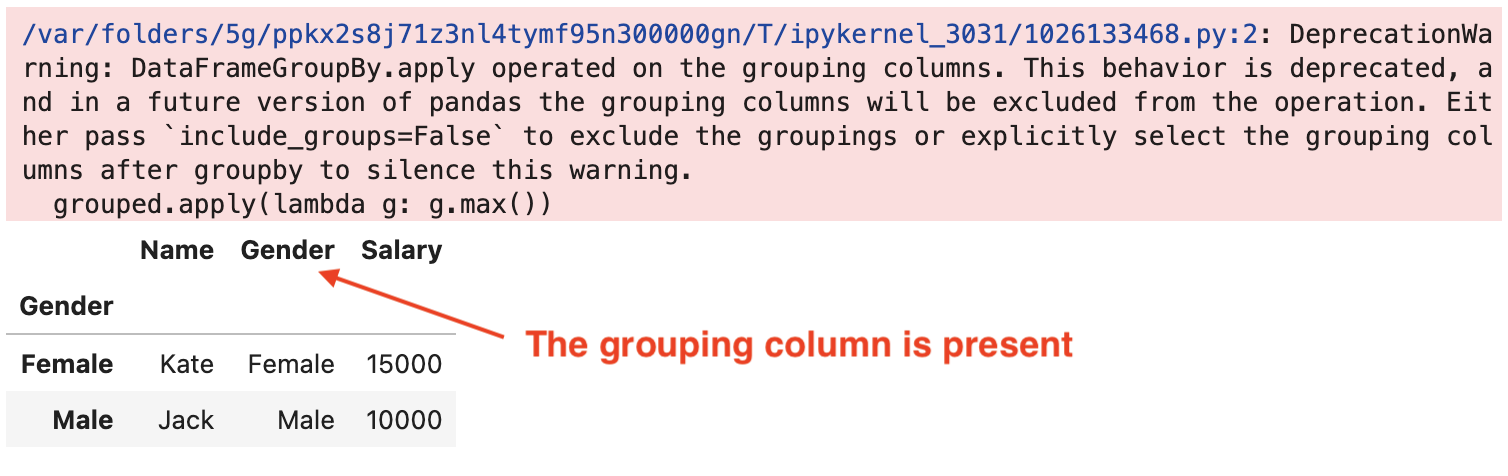
grouped = df.groupby('Gender')Let’s apply a function to find the maximum salary values within each gender group:
grouped.apply(lambda g: g.max())This triggers the warning because the Gender column, used for grouping, appears in the resulting DataFrame despite already being an index.
How to Fix the Warning
There are two ways to resolve this:
Option 1: Exclude the Grouping Column
Pass include_groups=False to explicitly exclude the grouping column from the output:
grouped.apply(lambda g: g.max(), include_groups=False)Option 2: Explicitly Select Desired Columns
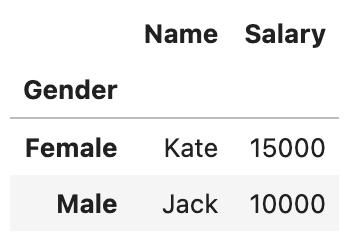
If you only want specific columns in the output, apply the function to a subset:
df.groupby('Gender')[['Name', 'Salary']].apply(lambda g: g.max())This ensures that only the selected columns are included in the final DataFrame.
Conclusion
This change in pandas helps avoid redundancy when working with grouped DataFrames. To future-proof your code and silence the warning, either set include_groups=False or explicitly select the columns you need.